# Kubernetes 使用总结
Kubernetes 简称 k8s,是 google 在 2014 年发布的一个开源项目。
Kubernetes 解决了哪些问题?
真实的生产环境应用会包含多个容器,而这些容器还很可能会跨越多个服务器主机部署。Kubernetes 提供了为那些工作负载大规模部署容器的编排与管理能力。Kubernetes 编排让你能够构建多容器的应用服务,在集群上调度或伸缩这些容器,以及管理它们随时间变化的健康状态。
- kubernetes 基础
- kubernetes 优化
- kubernetes 实战
Kubernetes 基础概念很多,第一次接触容易看晕,如果是新手,建议直接看实战部分,先跑起来再说。
# kubernetes 基础
k8s 中有几个重要概念。
| 概念 | 介绍 |
|---|---|
| cluster | 一个 k8s 集群 |
| master | 集群中的一台机器,是集群的核心,负责整个集群的管理和控制 |
| node | 集群中的一台机器,是集群中的工作负载节点 |
| pod | k8s 最小调度单位,每个 pod 包含一个或多个容器 |
| label | 一个 key = value 键值对,可以附加到各种资源对象上,方便其他资源进行匹配 |
| controller | k8s 通过 controller 来管理 pod |
| service | 对外提供统一的服务,自动将请求分发到正确的 pod 处 |
| namespace | 将 cluster 逻辑上划分成多个虚拟 cluster,每个 cluster 就是一个 namespace |
# Cluster
Cluster 代表一个 k8s 集群,是计算、存储和网络资源的集合,k8s 利用这些资源运行各种基于容器的应用。
# Master 节点
Master 是 cluster 的大脑,运行着的服务包括 kube-apiserver、kube-scheduler、kube-controller-manager、etcd 和 pod 网络。
- kube-apiserver
- apiserver 是 k8s cluster 的前端接口,提供 restful api。各种客户端工具以及 k8s 其他组件可以通过它管理 cluster 中的各种资源。
- kube-scheduler
- 负责决定将 pod 放在哪个 node 上运行,scheduler 在调度时会充分考虑 cluster 中各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
- kube-controller-manager
- 负责管理 cluster 各种资源,保证资源处理预期状态。controller-manager 由多种 controller 组成,包括 replication controller,endpoint controller,namespace controller,serviceaccount controller 等。
- 不同的 controller 管理不同的资源,例如:replication controller 管理 deployment ,statefulset,damonset 的生命周期,namespace controller 资源管理 namespace 资源。
- etcd(分布式 key-value 存储库)
- 负责保存 cluster 的配置信息和各种资源的状态信息。当数据发生变化时,etcd 会快速地通知 k8s 相关组件。
- pod 网络
- pod 要能够通信,cluster 必须部署 pod 网络,flannel 是其中一个可选方案。
# Node 节点
Node 节点 是 pod 运行的地方。node 节点上运行的 k8s 组件有 kubelet、kube-proxy 和 pod 网络。
- kubelet
- kubelet 是 node 节点的代理,当 master 节点中 kube-scheduler 确定在某个 node 节点上运行 pod 后,会将 pod 的具体配置信息发送给该节点的 kubelet,kubelet 根据这些信息创建和运行容器,并向 master 节点报告运行状态。
- kube-proxy
- 每个 node 节点都会运行 kube-proxy 服务,它负责将访问 service 的请求转发到后端的容器。如果有多个副本,kube-proxy 会实现负载均衡。
- pod 网络
- pod 要能够相互通信,k8s cluster 必须部署 pod 网络,flannel 是其中一个可选方案。
# Pod
每一个 pod 包含一个或多个 container,pod 中的容器作为一个整体被 master 调度到 node 节点上运行。
为什么 k8s 使用 pod 管理容器,而不是直接操作容器?
1、因为有些容器天生就是需要紧密的联系,放在一个 pod 中表示一个完整的服务,k8s 同时会在每个 pod 中加入 pause 容器,来管理内部容器组的状态。
2、Pod 中的所有容器共享 ip,共享 volume,方便进行容器之间通信和数据共享。
什么时候需要在 pod 中定义多个容器?
答:这些容器联系非常紧密,而且需要直接共享资源,例如一个爬虫程序,和一个 web server 程序。web server 强烈依赖爬虫程序提供数据支持。
# Label
Label 是一个 key = value 的键值对,其中 key 和 value 都由用户自己指定。
Label 的使用场景:
- kube-controller
- 通过 label selecter 筛选出要监控的 pod 副本,使 pod 副本数量符合预期。
- kube-proxy
- 通过 label selecter 选择对应的 pod,自动建立每个 service 到对应 pod 的请求转发路由表,从而实现 service 的智能负载均衡机制。
- 通过对 node 定义 label,在 pod 中使用 node selector 匹配,kube-scheduler 进程可以实现 pod 定向调度的特性。
总之,label 可以给对象创建多组标签,label 和 label selecter 共同构建了 k8s 系统中核心的应用模型,使得被管理对象能够被精细地分组管理,同时实现了整个集群的高可用性。
# Controller
k8s 通常不会直接创建 pod,而是通过 controller 来管理 pod。controller 中定义了 pod 的部署特性,比如有几个副本,在什么样的 node 上运行等。为了满足不同的业务场景,k8s 提供了多种类型的 controller。
- Deployment
- 最常使用,可以管理 pod 多个副本,并确保 pod 按照期望的状态运行,底层调用 ReplicaSet。
- ReplicaSet
- 实现 pod 的多副本管理,通常使用 Deployment 就够了。
- DaemonSet
- 用于每个 node 最多只运行一个 pod 副本的场景。
- 使用场景
- 在集群的每个节点上运行存储 Daemon,比如 glusterd 或 ceph。
- 在每个节点上运行日志搜集 Daemon,比如 flunentd 或 logstash。
- 在每个节点上运行监控,比如 Prometheus Node Exporter 或 collected。
- StatefuleSet
- 能够保证 pod 的每个副本在整个生命周期中名称是不变的,而其他 controller 不提供这个功能。
- Job
- 用于运行结束就删除的应用,而其他 controller 中的 pod 通常是长期持续运行。
提示
使用 deployment controller 创建的用例,如果出现有 pod 挂掉的情况,会自动新建一个 pod,来维持配置中的 pod 数量。
# Job
容器按照持续运行时间可分为两类:服务类容器和工作类容器。
服务类容器通常持续提供服务,需要一直运行,比如 http server。工作类容器则是一次性任务,比如批处理程序,完成后容器就退出。
Controller 中 deployment、replicaSet 和 daemonSet 类型都用于管理服务类容器,对于工作类容器,我们使用 job。
# Service
Service 是可以访问一组 pod 的策略,通常称为微服务。具体访问哪一组 pod 是通过 label 匹配出来的。service 为 pod 提供了负载均衡,原理是使用 iptables。
为什么要用 service ?
- pod 是有生命周期的,它们可以被创建,也可以被销毁,然而一旦被销毁生命就永远结束。而 pod 在一个 k8s 集群中可能经常性的创建,销毁,每一次重建都会产生一个新的 ip 地址。
- service 从逻辑上代表了一组 pod,具体是哪些 pod 是由 label 来挑选的。service 有自己的 ip,而且这个 ip 是不变的,客户端只需要访问 service 的 ip,k8s 则负责建立和维护 service 与 pod 的映射关系,无论 pod 如何变化,对客户端不会有任何影响,因为 service 没有变。
外网如何访问 service?
- ClusterIP:通过集群的内部 ip 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的 ServiceType。
- NodePort:通过每个 node 上的 ip 和端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求
nodeip:nodeport,可以从集群的外部访问一个 service 服务。 - LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。 没有任何类型代理被创建,这只有 k8s 1.7 或更高版本的 kube-dns 才支持。
# Namespace
如果有多个用户使用同一个 k8s cluster,如何将他们创建的 controller,pod 等资源分开呢?
答:使用 namespace。
如果将物理的 cluster 逻辑上划分成多个虚拟 cluster,每个 cluster 就是一个 namespace,不同 namespace 里的资源是完全隔离的。
k8s 默认创建了两个 namespace。
- default 创建资源时如果不指定,将会放到这个 namespace 中。
- kube-system 存放 k8s 自己创建的系统资源。
# Kubernetes 优化
- 健康检查
- 数据管理
- 密码管理
- 集群监控
# 健康检查
强大的自愈能力是 k8s 这类容器编排引擎的一个重要特性。自愈的默认实现方式是自动重启发生故障的容器。除此之外,用户还可以利用 liveness 和 readiness 探测机制设置更精细的健康检查,进而实现如下需求:
- 零停机部署
- 避免部署无效的镜像
- 更加安全的滚动升级
默认情况下,只有容器进程返回值非零,k8s 才会认为容器发生了故障,需要重启。如果我们想更加细粒度的控制容器重启,可以使用 liveness 和 readiness。
liveness 和 readiness 的原理是定期检查 /tmp/healthy 文件是否存在,如果存在即认为程序没有出故障,如果文件不存在,则会采取相应的措施来进行反馈。
liveness 采取的策略是重启容器,而 readiness 采取的策略是将容器设置为不可用。
如果需要在特定情况下重启容器,可以使用 liveness。
如果需要保证容器一直可以对外提供服务,可以使用 readiness。
我们可以将 liveness 和 readiness 配合使用,使用 liveness 判断容器是否需要重启,用 readiness 判断容器是否已经准备好对外提供服务。
# 数据管理
上文说道,pod 可能会被频繁地销毁和创建,当容器销毁时,保存在容器内部文件系统中的数据都会被清除。为了持久化保存容器的数据,可以使用 k8s volume。
Volume 的生命周期独立于容器,pod 中的容器可能被销毁和重建,但 volume 会被保留。实质上 vloume 是一个目录,当 volume 被 mount 到 pod,pod 中的所有容器都可以访问到这个 volume。
Volume 支持多种类型。
- emptyDir
- 数据存放在 pod 中,对 pod 中的容器来说,是持久的,只要 pod 还在数据就还在。
- hostPath
- 数据存在主机上,主机在数据就在。
- AWS Elastic Block Store
- 数据存在云服务器上。
- Persistent Volume
- 自定义一块外部存储空间 Persistent Volume,然后在创建 pod 时使用 PersistentVolumeClaim(PVC)去申请空间,并进行存储。
Volume 提供了对各种类型的存放方式,但容器在使用 volume 读写数据时,不需要关心数据到底是存放在本地节点的系统中还是云硬盘上。对容器来说,所有类型的 volume 都只是一个目录。
# 密码管理
应用程序在启动过程中可能需要一些敏感信息,比如访问数据库的用户名和密码。将这些信息直接保存在容器镜像中显然不妥,k8s 提供的解决方案是 secret。
secret 会以密文的方式存储数据,避免直接在配置文件中保存敏感信息。secret 会以 volume 的形式被 mount 到 pod,容器可通过文件的方式使用 secret 中的敏感数据,此外容器也可以按环境变量的形式使用这些数据。
使用配置文件创建 mysecret.yaml:
apiVersion: v1
kind Secret
metadata:
name:mysecret
data:
username:admin
password:123
2
3
4
5
6
7
保存配置文件后,然后执行kubectl apply -f mysecret.yaml进行创建。
在 pod 中使用创建好的 secret:
# mypod.yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mengsixing/notepad
volumeMounts:
- name: foo
mountPath: "etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
执行kubectl apply -f mypod.yaml 创建 pod,并使用 secret。创建完成后,secret 保存在容器内 /etc/foo/username ,/etc/foo/password 目录下。
# 集群监控
创建 k8s 集群并部署容器化应用只是第一步。一旦集群运行起来,我们需要确保集群一切都是正常的,这就需要对集群进行监控。
常用的可视化监控工具如下。
- Weave Scope
- Heapster
- Prometheus Operator
具体的使用步骤就直接看文档了,这里不详细说明。
通过集群监控我们能够及时发现集群出现的问题,但为了方便进一步排查问题,我们还需要进行进行日志记录。
常用的日志管理工具如下。
- Elasticsearch 负责存储日志并提供查询接口。
- Fluentd 负责从 k8s 搜集日志并发送给 Elasticsearch。
- Kibana 提供一个可视化页面,用户可以浏览和搜索日志。
# Kubernetes 实战
我们来实战部署一个 k8s 记事本项目,项目使用 mengsixing/notepad (opens new window) 镜像进行构建,该镜像在部署后会在 8083 端口上提供一个 web 版记事本服务,查看演示 (opens new window)。
为了避免安装 k8s 出现的各种坑,这里使用 Play with Kubernetes (opens new window)进行演示。
首先在 Play with Kubernetes 上创建 3 台服务器,node1 作为 master 节点,node2 和 node3 作为工作节点。接下来进行以下操作;
- 创建一个集群 cluster
- 加入 node 节点
- 初始化 cluster 网络
- 创建 controller
- 创建 service
- 执行部署
# 创建一个集群 cluster
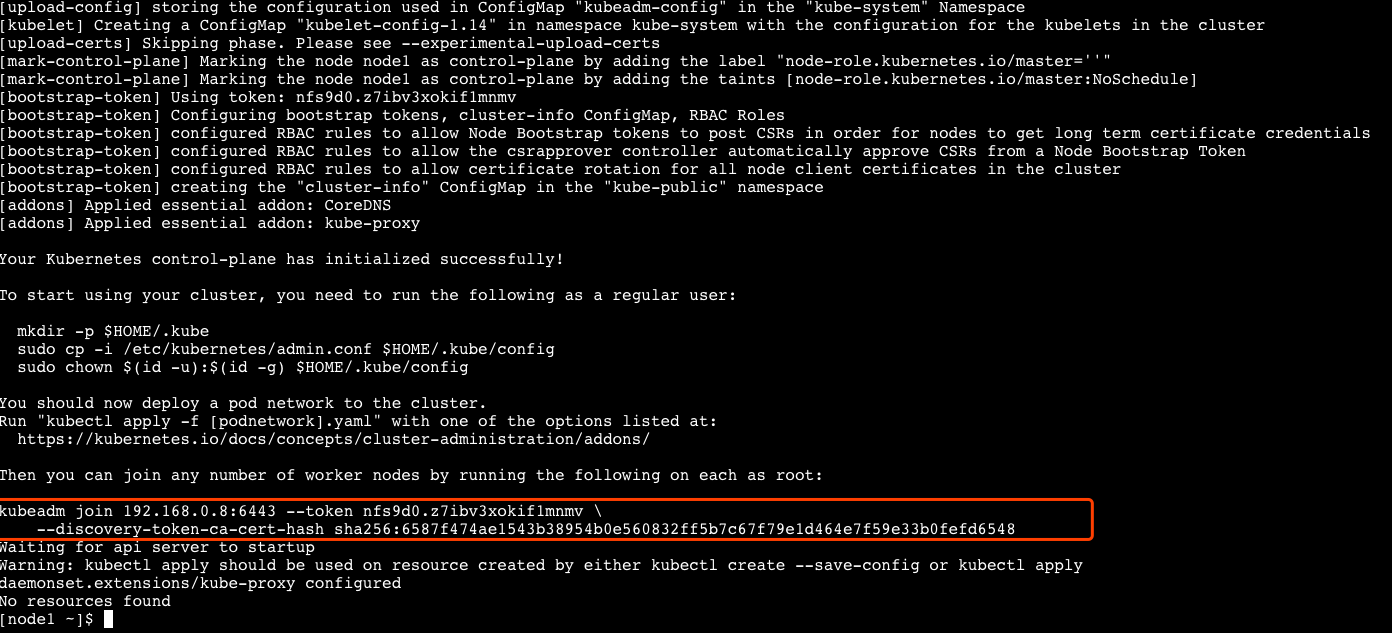
在 node1 上运行 kubeadm init 即可创建一个集群。
kubeadm init --apiserver-advertise-address $(hostname -i)
执行完成后会生成 token,这样其他节点就可以凭借这个 token 加入该集群。
# 加入 node 节点
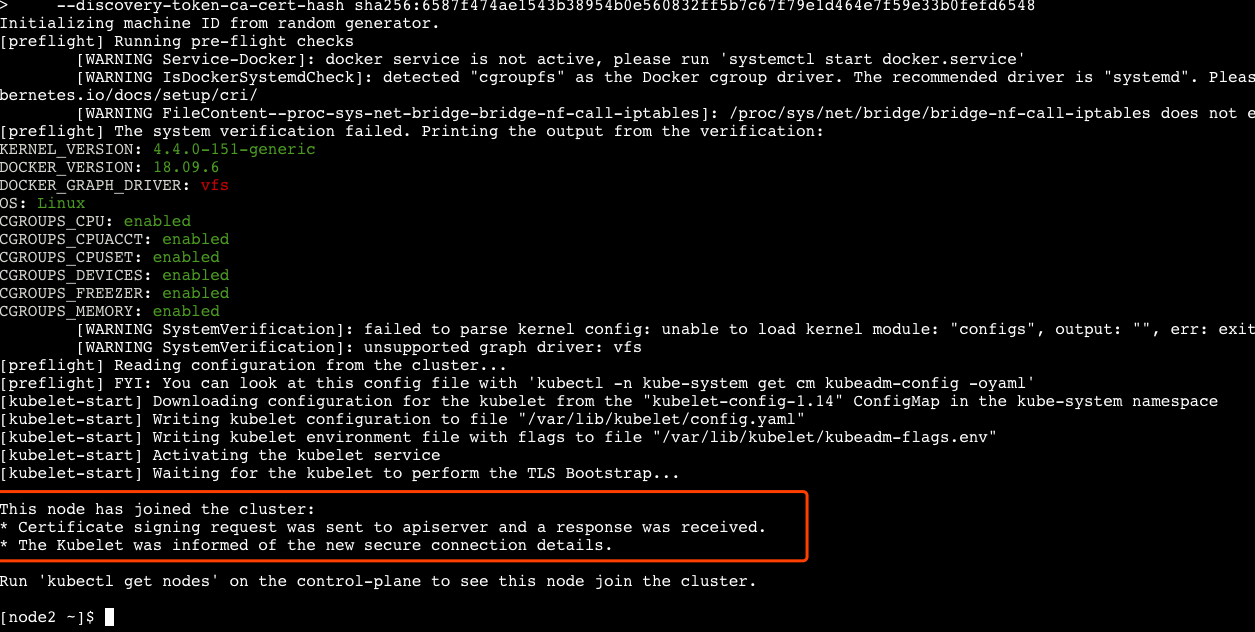
在 node2 和 node3 机器上,分别执行以下命令,加入到 node1 的集群。
kubeadm join 192.168.0.8:6443 --token nfs9d0.z7ibv3xokif1mnmv \
--discovery-token-ca-cert-hash sha256:6587f474ae1543b38954b0e560832ff5b7c67f79e1d464e7f59e33b0fefd6548
2
命令执行完毕后,即可看到 node2,node3 已经加入成功。
# 查看集群状态
在 node1 节点上,执行以下命令。
kubectl get node
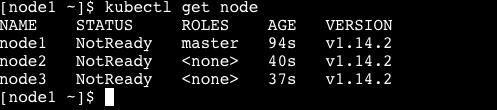
可以看到,集群中存在 node1 ,node2,node3 这 3 个节点,但这 3 个节点的都是 NotReady 状态,为什么?
答:因为没有创建集群网络。
# 创建集群网络
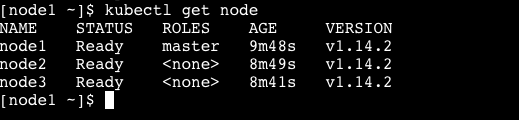
执行以下代码创建集群网络。
kubectl apply -n kube-system -f \
"https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 |tr -d '\n')"
2
执行命令后,稍等一下,然后查看 node 状态,可以看到,集群中的 3 个节点都是 Ready 状态了。
# 创建 Deployment
我们通过配置文件来创建 deployment,新建 deployment.yaml 文件,内容如下:
# 配置文件格式的版本
apiVersion: apps/v1
# 创建的资源类型
kind: Deployment
# 资源的元数据
metadata:
name: notepad
# 规格说明
spec:
# 定义 pod 数量
replicas: 3
# 通过 label 找到对应的 pod
selector:
matchLabels:
app: mytest
# 定义 pod 的模板
template:
# pod 的元数据
metadata:
# 定义 pod 的 label
labels:
app: mytest
# 描述 pod 的规格
spec:
containers:
- name: notepad
image: mengsixing/notepad
ports:
- containerPort: 8083
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
文件创建之后,执行命令:
kubectl apply -f ./deployment.yaml
# deployment.apps/notepad created
2
查看部署的 pod。

可以看到,我们使用 deployment 类型的 controller 创建了 3 个 pod,分别运行在 node2 和 node3 机器上,如果有更多的机器,也会自动负载均衡,合理地分配到每个机器上。
# 创建 Service
创建 service 和 deployment 类似,新建 service.yaml 文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
# 在节点上部署访问 pod 的端口
type: NodePort
ports:
- port: 80
# service 代理的端口
targetPort: 8083
# node 节点上提供给集群外部的访问端口
nodePort: 30036
# 匹配 pod
selector:
app: mytest
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
文件创建之后,执行命令:
kubectl apply -f ./service.yaml
# service/my-service created
2
# 查看创建结果
使用 kubectl get deployment 和 kubectl get service 查看创建结果。

可以看到,deployment 和 service 均创建成功,并且已知 service 暴露的 ip 地址为:10.106.74.65,端口号为 80,由于设置了 targetPort,service 在接收到请求时,会自动转发到 pod 对应的 8083 端口上。
# 访问部署结果
部署成功后,我们可以通过两种方式进行访问:
- 集群内:通过 service 的 clusterIp + port 端口进行访问。
- 集群外:通过任意一个 node 节点 + nodePort 端口进行访问。
# 集群内访问
curl 10.106.74.65
# 集群外访问
# 192.168.0.12 是 node2 节点的ip
# 192.168.0.11 是 node3 节点的ip
curl 192.168.0.12:30036
curl 192.168.0.11:30036
2
3
4
5
6
7
集群内访问。
集群外访问。
到这里,已经算部署成功了,大家肯定有疑问,部署一个如此简单的 web 应用就这么麻烦,到底 k8s 好在哪里?我们接着往下看。
# K8s 运维
项目已经部署,接下来来实战一个运维,感受一下 k8s 带给我们的便利。
# 案例 1
公司要做双 11 活动,需要至少 100 个容器才能满足用户要求,应该怎么做?
首先,应该尽可能利用当前拥有的服务器资源,创建更多的容器来参与负载均衡,通过 docker stats 可以查看容器占用的系统资源情况。如果充分利用后仍然不能满足需求,就根据剩余需要的容器,计算出需要购买多少机器,实现资源的合理利用。
- 购买服务器,将服务器作为 node 节点,join 到集群中。
- 执行扩容命令。
执行以下命令就能将容器扩展到 100 个。
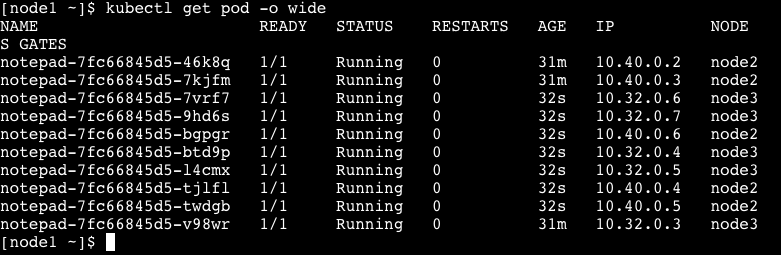
kubectl scale deployments/notepad --replicas=100
如图,扩展 10 个 pod 的情况,node2 和 node3 节点共同分担负载。
也可以通过修改 deployment.yaml 中的 replicas 字段,执行 kubectl apply -f deployment.yaml去执行扩展。如果活动结束了,只需要将多余的服务器删除,缩减容器数量即可还原到之前的效果。
# 案例 2
双 11 活动很火爆,但突然加了需求,需要紧急上线,如果实现滚动更新?
滚动更新就是在不宕机的情况下,实现代码更新。执行以下命令,修改 image 即可。
kubectl set image deployments/notepad notepad=mengsixing/notepad:new
也可以通过修改 deployment.yaml 中的 image 字段,执行 kubectl apply -f deployment.yaml去执行升级。
如果更新出了问题,k8s 内置了一键还原上个版本的命令:
kubectl rollout undo deployments/notepad
通过这 2 个案例,感觉到了 k8s 给运维带来了很大的便利:快速高效地部署项目,支持动态扩展、滚动升级,同时还能按需优化使用的硬件资源。
# 总结
本文的目的就是入门 k8s,通过一个简单的集群来实现这一点,但其中也踩了好多坑,具体如下:
- 使用 minikube 搭建项目
- 能快速搭建一个单节点 k8s 环境。
- 但在本地使用 minikube 搭建一套 k8s 集群,很多包装不上,全局代理也不行。
- 使用 google clould 上的服务器
- 在 gogole clould 上,解决了网络问题,需要安装的包都能装上。
- 但由于是新服务器,需要各种安装环境,docker,kubeadm,kubectl 等,安装过程繁琐,还可能会遇到报错。
- 不知道哪天手滑了一下,试用账号变成了付费账号,赠金 $300 就这样没了 😭。
- 使用 play with kubernetes
- k8s 所需环境不用配,已经装好了,这一点很不错。
- 单台机器容量太小,稍微大一点的镜像就安装不进去了。
- 偶尔使用 play with kubernetes 时,刚新建完一个实例,就被踢下线,遇到这种情况就没法玩。
- 没有提供公网 ip,无法验证外网访问情况。
最后,推荐一下《每天 5 分钟玩转 Kubernetes》这本书,一本非常适合入门 k8s 的实战书。书中通过大量的简单实战,从易到难,让我真正理解了 k8s,本文中的大量理论知识也都来自这本书。
← 微前端自检清单 Docker 使用总结 →